Table of Contents
- Intro
- What is a Thread
- Threading use cases
- Python
threadingfirst steps - Visualizing multihreading times with
threadingmodule ThreadPoolExecutor- Other Resources
Intro
This post is an introduction to multithreading in Python with the threading module and the ThreadPoolExecutor class from the concurrent.futures module.
The resources section at the end has some links to wonderful material that you can use to go deeper into the topic 🤓
Related posts
The code from this post can be found in this repository.
What is a Thread
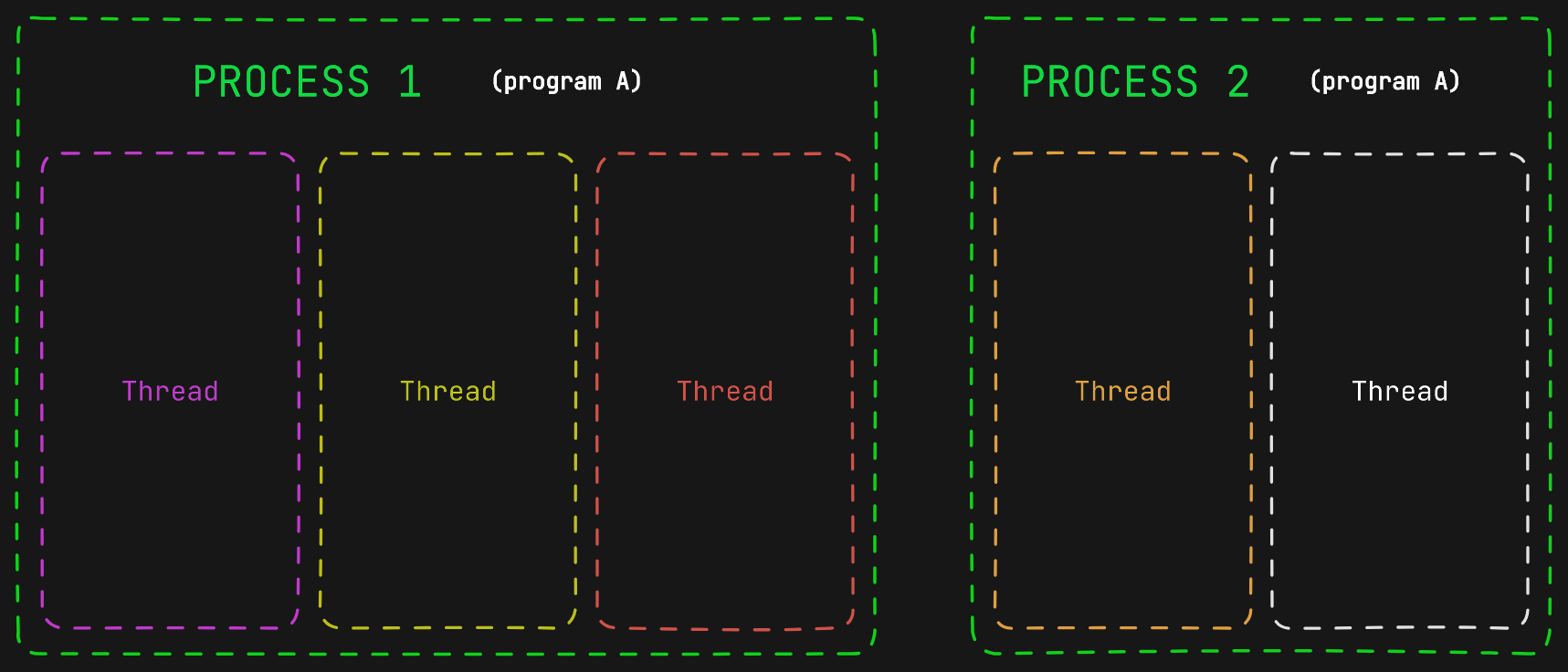
A thread is the basic unit of execution within a process. It is an independent flow of execution that shares the same address space as other independent flows of execution within the same process. A process can have one or more threads, one of them is the main thread, which is the default thread of a Python process.
📘 In Python we can use the threading module to write programs that use multiple threads, a well as the ThreadPoolExecutor class from the concurrent.futures module.
If we write the program so it makes use of several threads, then the program will be able to run concurrently in one core. It is also possible executing a one thread program concurrently by using coroutines.
The threads within each Python (CPython implementation) process cannot run in parallel even when multiple cores are available because of Python’s Global Interpreter Lock (GIL), unlike threads in other programming languages such as Java, C/C++, and Go. If you have CPU-bound operations and need parallel implementation in Python you should use the multiprocessing module or the ProcessPoolExecutor class (see Multiprocessing in Python).
Imagine that we write a program that will become a single process when it starts execution. Also, the process will have two threads. When there are two threads it is possible to start playing with concurrency.
In a single-core CPU it is possible for the program to execute concurrently. With one core and two threads, the threads can be switched one for the other in the same core. That is called context switching.
During a context switch, one thread is switched out of the CPU so another thread can run. For this purpose, the state of the process or thread is stored, so that it can be restored and resume execution at a later point, and then another previously saved state is restored.
Context switching is usually computationally expensive, switching from one process or thread to another requires a certain amount of time for saving and loading registers and other operations. Switch context between threads is generally faster than between processes.
Threading use cases
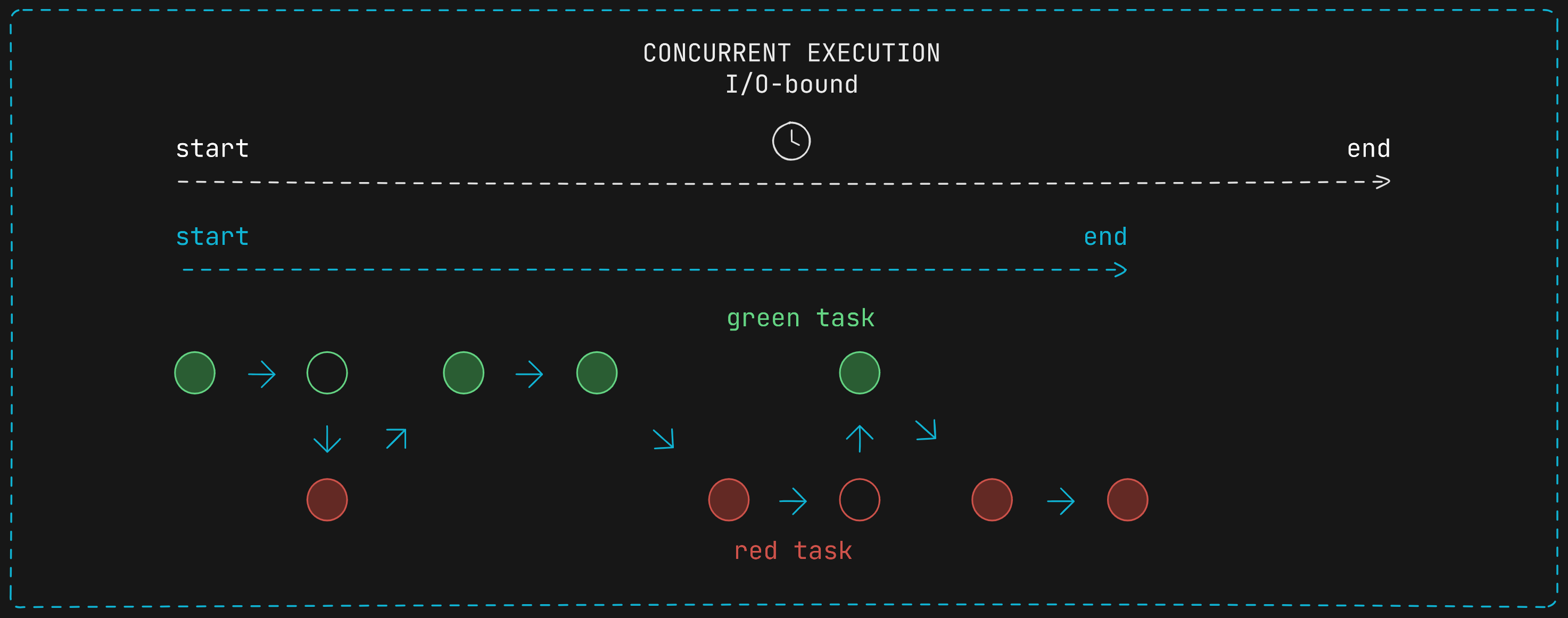
The tasks where multithreading is best suited for use are I/O-bound operations. For example, if a thread executes an instruction that has to make a request to a database, it would not make sense to block the CPU core with a thread waiting for a response. Instead, it would be a better use of resources to allow another thread to use the core while the first thread is waiting.
In the figure below the empty circles represent I/O operations where the thread keeps waiting for something to occur. When the first I/O operation begins (empty green circle) the operative system quickly switch the waiting thread for the red one in order to better allocate computational resources. This is a decision taken by the OS, the developer cannot decide when to switch between threads.
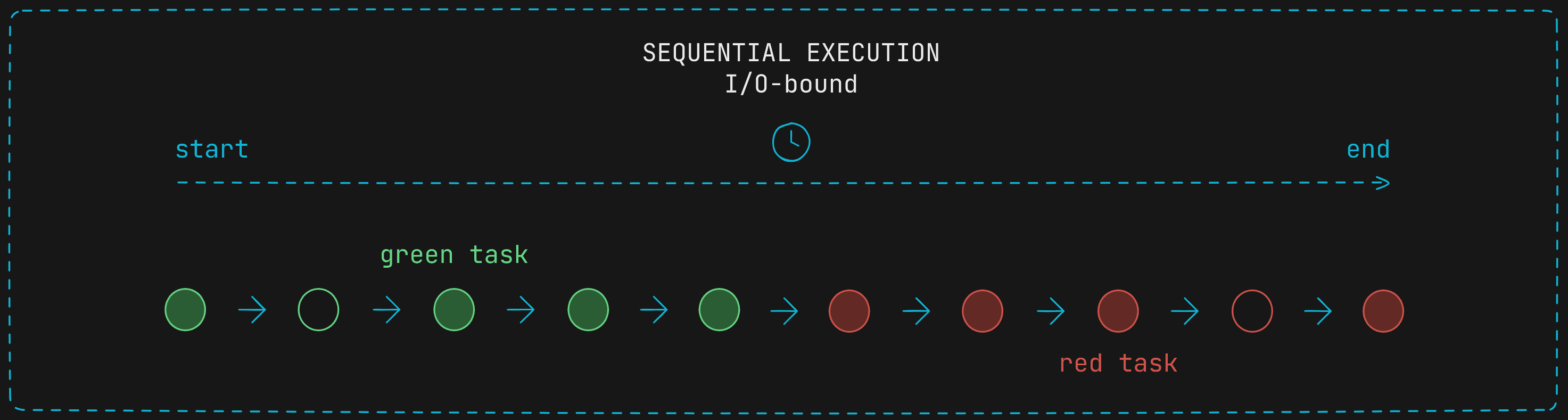
If the program does not use multiples threads running concurrently and instead it runs tasks within a single thread sequentially, it would need to wait for the green task to complete to begins the execution of the red task, so it would spend more time to complete both tasks.
So when dealing with I/O operations multithreading is a good choice to achieve a better allocation of resources.
Now let’s see some implementations of multithreaded programs! 🥷🏽
Python threading first steps
First let’s define the I/O-bound and the CPU-bound tasks. The io_bound_operation just sleeps as long as the number of seconds specified. The cpu_bound_operation adds the range of numbers specified. Both functions append the results to the shared_list. Remember that threads in the same process can share data.
import logging
from threading import Thread
from time import perf_counter, sleep
from concurrency.utils import flaten_list_of_lists, get_saving_path, postprocess_times
from concurrency.visualize import barh
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S")
shared_list = [] # threads from the same process share data
def io_bound_operation(secs: float | int) -> None:
"""Run 1 I/O-bound task of secs seconds and append the results to shared_list."""
start = perf_counter()
sleep(secs)
finish = perf_counter()
shared_list.append([(start, finish)])
def cpu_bound_operation(n: int) -> None:
"""CPU-bound task."""
start = perf_counter()
count = 0
for i in range(n):
count += i
finish = perf_counter()
shared_list.append([(start, finish)])
Now we are going to create two new threads: t1 and t2. When instantiating the Thread object, we need to add the target, which is the task/function we want to run in the thread. Arguments can be passed via the args parameter, which accepts an Iterable object.
For this example, we will make the I/O-bound operation last for 1 second, while my processor takes approximately 3.5 seconds to add those 100,000,000 numbers.
def threading_two_threads():
# Create two thread objects
t1 = Thread(target=io_bound_operation, args=(1,))
t2 = Thread(target=cpu_bound_operation, args=(100000000,))
# Start activity -> invokes run() method
t1.start()
sleep(0.1)
t2.start()
# Block the calling thread -> Avoids continuing to run without threads
# being finished
t1.join()
t2.join()
logging.info(f"shared_list {shared_list}")
Then we need to start the thread’s activity. This is done by calling the start() method. It arranges for the object’s run() method to be invoked in a separate thread of control.
Also, there is a sleep(0.1) function to make the second thread start a bit later. It will help us to better visualize.
def threading_two_threads():
# Create two thread objects
t1 = Thread(target=io_bound_operation, args=(1,))
t2 = Thread(target=cpu_bound_operation, args=(100000000,))
# Start activity -> invokes run() method
t1.start()
sleep(0.1)
t2.start()
# Block the calling thread -> Avoids continuing to run without threads
# being finished
t1.join()
t2.join()
logging.info(f"shared_list {shared_list}")
Finally, we must call the Thread object’s join() method if we want to wait until the thread terminates.
The main thread will not exit until both threads have completed.
By joining the threads we are blocking the calling thread (main thread) until the thread whose join() method is called terminates — either normally or through an unhandled exception or until the optional timeout occurs.
You can play with this example, if you comment both join() methods the program will raise an exception, since there will be nothing in the shared_list and the postprocess_times function will try to index the empty list.
def threading_two_threads():
# Create two thread objects
t1 = Thread(target=io_bound_operation, args=(1,))
t2 = Thread(target=cpu_bound_operation, args=(100000000,))
# Start activity -> invokes run() method
t1.start()
sleep(0.1)
t2.start()
# Block the calling thread -> Avoids continuing to run without threads
# being finished
t1.join()
t2.join()
logging.info(f"shared_list {shared_list}")
In order to visualize the time spent by the threads the threading_two_threads function has a couple of additional functions to postprocess and plot them on the horizontal bar chart. The code can be found in the repo.
def threading_two_threads():
# Create two thread objects
t1 = Thread(target=io_bound_operation, args=(1,))
t2 = Thread(target=cpu_bound_operation, args=(100000000,))
# Start activity -> invokes run() method
t1.start()
sleep(0.1)
t2.start()
# Block the calling thread -> Avoids continuing to run without threads
# being finished
t1.join()
t2.join()
logging.info(f"shared_list {shared_list}")
# Just some processing for chart
start_points, end_points = postprocess_times(flaten_list_of_lists(shared_list))
# start_points, end_points = postprocess_times(shared_list)
barh(
title="Concurrent execution, 2 threads, 1 I/O-bound task of 1s + 1 \
CPU-task of 3.5s approx",
start_points=start_points,
end_points=end_points,
path=get_saving_path("threading/images/first_multithreaded_program.png"),
n=2,
)
if __name__ == "__main__":
logging.info(f"Init concurrent tasks")
threading_two_threads()
logging.info(f"Finish concurrent tasks")
The image below shows the time spent by each thread to complete. The sleep function makes the second thread (cpu_bound_operation) start a little later. The first thread (0 in the graph) starts and 0.1 seconds later the second one starts.
As the I/O-bound task only lasts for 1 second and the function io_bound_operation only has to do that operation, during the time that the I/O-bound task is waiting (the whole second) the CPU-bound task can be executing. That is why the CPU-bound task (second thread) only lasts 3.5 seconds approximately and is not delayed by the I/O-bound task.
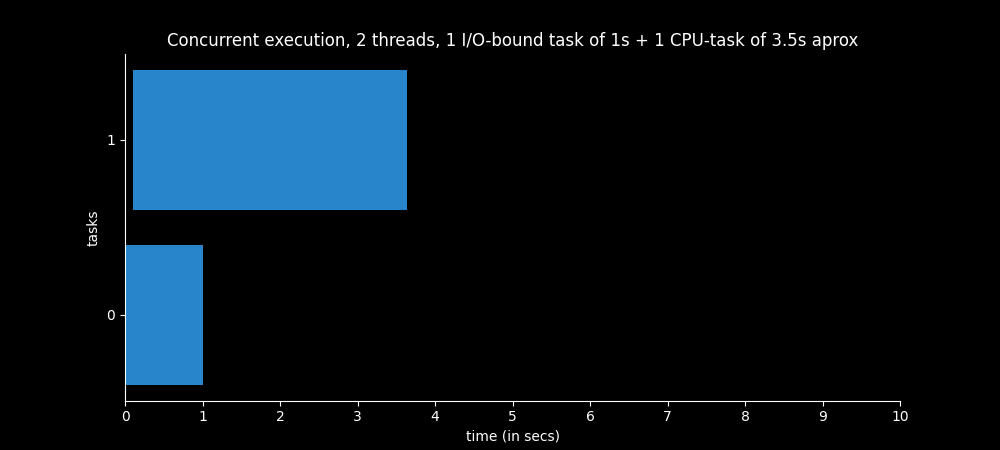
The Thread object is a naive way of creating threads, there are more convenient ways of doing it. However, let’s look a some more simple examples before delving a little deeper.
Visualizing multihreading times with threading module
Example 1 - 2 threads
Thread 1 - 1 I/O-bound operation of 1s and 1 CPU-bound operation of 1s approx.
Thread 2 - 1 CPU-bound task of 3.5 seconds approximately
Now let’s consider that the first thread runs a task consisting of a CPU-bound operation of approximately 1 second and an I/O-bound operation of 1 second instead of having a task that only executes an I/O-bound operation.
So now we have a program that creates two new threads, one running an I/O-bound operation and a CPU-bound operation and another running the CPU-bound operation of 3.5 seconds approximately.
def cpu_io_bound_operations(secs: float | int, n: int) -> None:
"""Run 1 function that execute 1 I/O-bound task of secs seconds and 1 CPU-bound task.
Append the results to shared_list."""
start = perf_counter()
count = 0
for i in range(n): # CPU-bound
count += i
sleep(secs) # I/O-bound
finish = perf_counter()
shared_list.append([(start, finish)])
The thread 2 needs 3.5 seconds of processor approximately, while the thread 1 only needs 1 second.
The thread 1 only needs 1 second due to the CPU-bound operation, since the waiting time of the I/O-bound task can be used by the thread 2.
If we add 3.5s (thread 2) + 1s (thread 1) we have 4.5s of CPU work.
The graph below shows just that, both tasks together last 4.5 seconds. The time required by each CPU-intensive task may vary slightly.
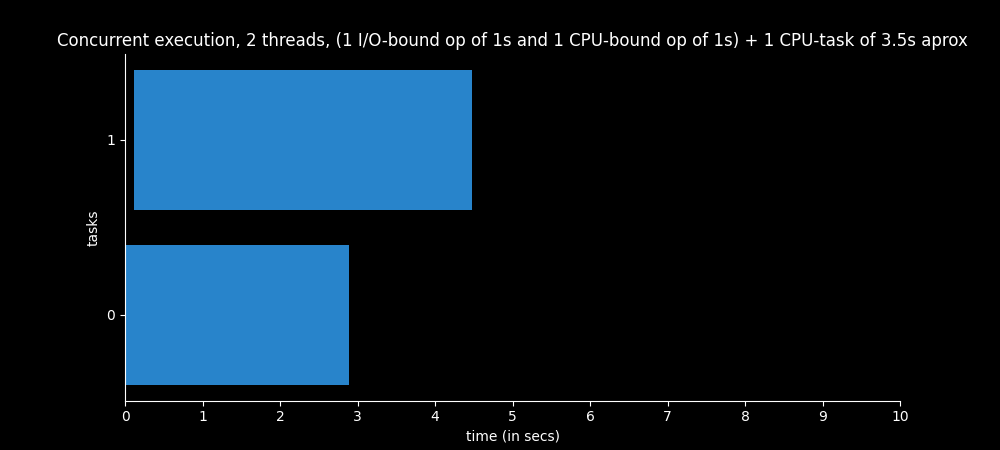
However, the thread 1 spends 3 seconds to terminate. That is because we don’t control when context switches occur, so the thread 1 may have been waiting some time to use the processor, even when the I/O-bound was terminated. Context switches are out of developer’s control, so they can occur more time than we actually would like and in moments we wouldn’t switch one thread for the other.
Now let’s take a quick look at some more examples! If you already got it you can skip this part and go directly to the next section: ThreadPoolExecutor 🚀
Example 2 - 1 thread
10 IO-bound operations of 1s sequentially
Here, we are representing a sequential execution and we don’t need to create more threads, the main thread is enough.
def sequential(n: int = 10, secs: float | int = 1) -> None:
"""Perform n I/O-bound operations of secs seconds sequentially in one thread
and plot a horizontal bar chart.
"""
# Perform n I/O-bound operations, save a tuple for each task
times = [io_bound_operation(secs) for _ in range(n)]
start_points, end_points = postprocess_times(times)
barh(
title="Sequential execution, 1 thread, 10 I/O-bound tasks of 1s",
start_points=start_points,
end_points=end_points,
path=get_saving_path("threading/images/ex_1_one_thread.png"),
)
In the figures above a thread was represented as a bar because each thread performed a task (even when we joined an I/O-bound and a CPU-bound operation we considered them as belonging to the same task).
Now we consider 10 different I/O-bound tasks executed in the same thread, so we can better visualize each task in a bar. So those ten bars belong to the same thread.
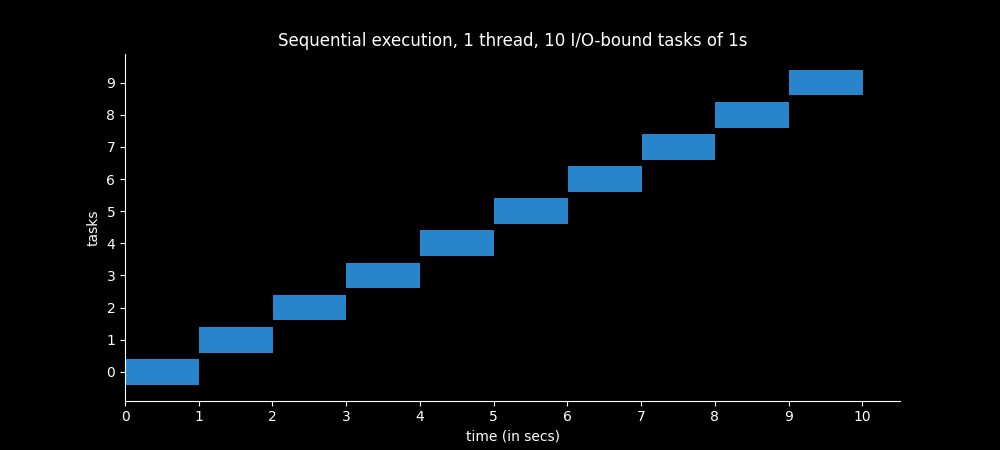
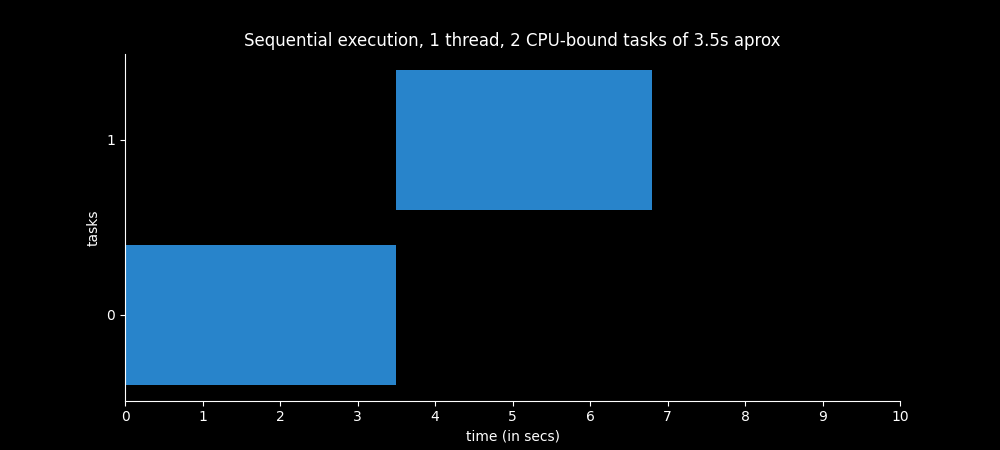
Example 3 - 1 thread
2 CPU-bound tasks
If we execute two CPU-bound tasks of 3.5 seconds approximately in the same thread sequentially we see that they take about 7 seconds to complete.
Before the second task begins, the first one have to complete.
def sequential(counts: int, n: int = 10) -> None:
# Perform n CPU-bound operations, save a tuple for each task
times = [cpu_bound_operation(counts) for _ in range(n)]
start_points, end_points = postprocess_times(times)
Example 4 - 2 threads
Thread 1 - 1 CPU-bound task of 3.5 seconds approximately
Thread 2 - 1 CPU-bound task of 3.5 seconds approximately
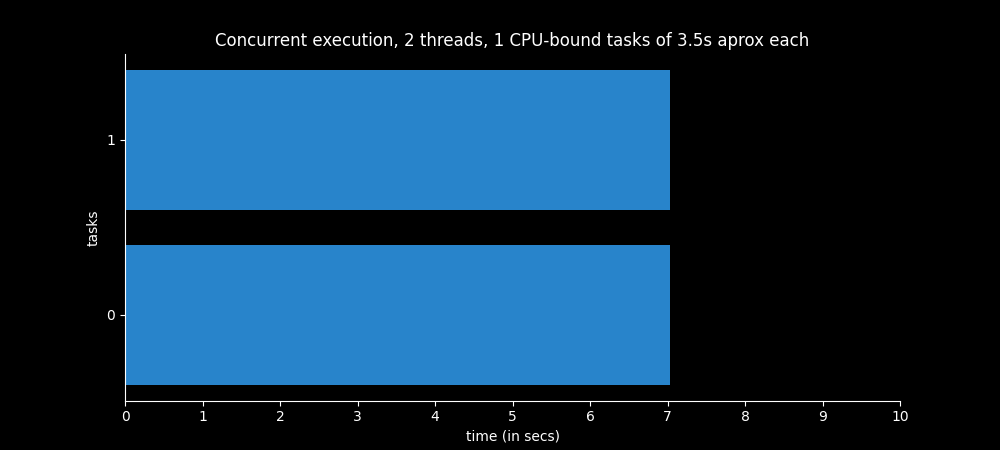
The same two CPU-bound tasks from above show a very different chart when we execute them concurrently. Both tasks seem to take 7 seconds, but in reality they take 3.5. They just switch back and forth until they are both finished.
This is not a proper use of multithreading, it is only for didactic purposes. There is no time improvement using multithreading with only CPU-bound tasks.
def thread_cpu_bound_operations(counts: int) -> None:
"""Run a CPU-bound task and append the results to shared_list."""
shared_list.append([cpu_bound_operation(counts)])
def threading_two_threads() -> None:
# Create two thread objects, each thread will perform five I/O-bound tasks
t1 = Thread(target=thread_cpu_bound_operations, args=(100000000,))
t2 = Thread(target=thread_cpu_bound_operations, args=(100000000,))
# Start activity -> invokes run() method
t1.start()
t2.start()
# Block the calling thread -> Avoids continuing to run without threads being finished
t1.join()
t2.join()
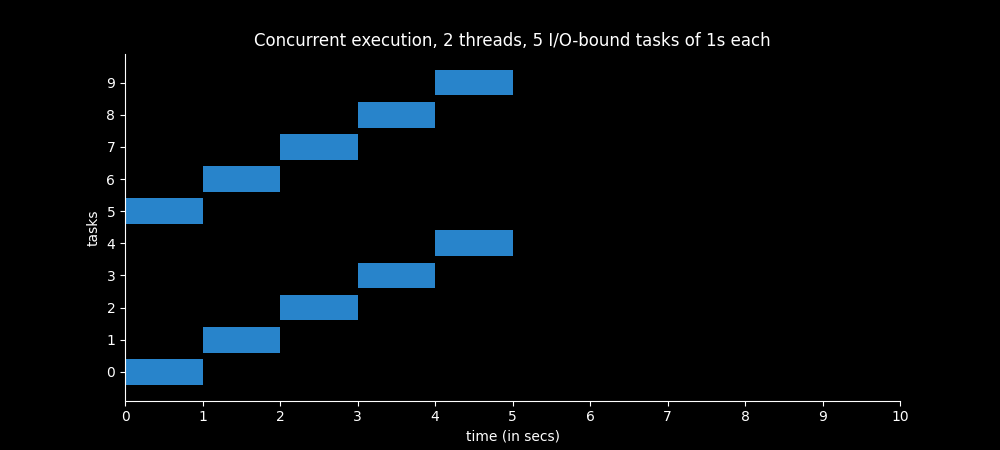
Example 5 - 2 threads
Thread 1 - 5 I/O-bound tasks of 1s each
Thread 2 - 5 I/O-bound tasks of 1s each
Ten I/O-bound tasks of 1 second and two threads. Each thread is in charge of executing five I/O-bound tasks sequentially, and both groups of five tasks are executed concurrently.
def thread_io_bound_operations(n: int, secs: float | int) -> None:
"""Run n I/O-bound tasks of secs seconds and append the results to shared_list."""
shared_list.append([io_bound_operation(secs) for _ in range(n)])
def threading_two_threads() -> None:
# Create two thread objects, each thread will perform five I/O-bound tasks
t1 = Thread(target=thread_io_bound_operations, args=(5, 1))
t2 = Thread(target=thread_io_bound_operations, args=(5, 1))
# Start activity -> invokes run() method
t1.start()
t2.start()
# Block the calling thread -> Avoids continuing to run without threads being finished
t1.join()
t2.join()
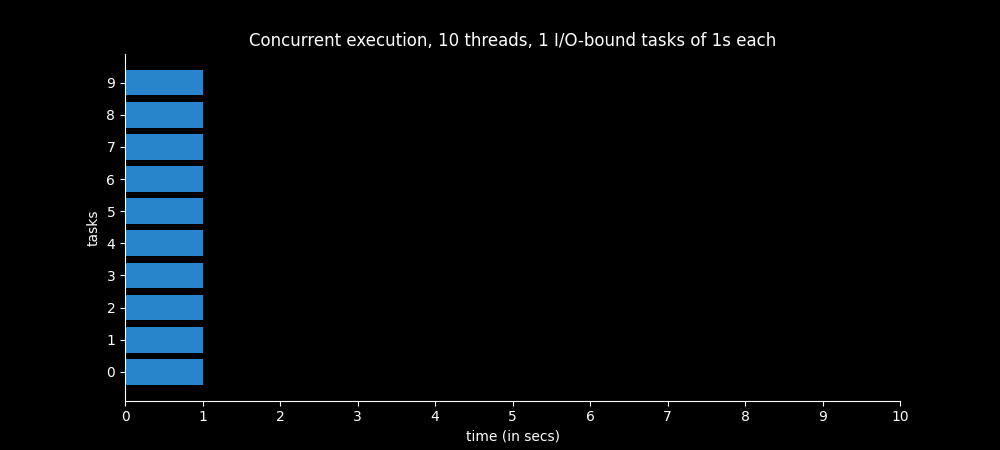
Example 6 - 10 threads
Each Thread - 1 I/O-bound task of 1s
Similar to the last example, but now we have ten threads instead of two, and each one is in charge of executing only one I/O-bound task of 1 second.
def thread_io_bound_operations(n: int, secs: float | int) -> None:
"""Run n I/O-bound tasks of secs seconds and append the results to shared_list."""
shared_list.append([io_bound_operation(secs) for _ in range(n)])
def threading_two_threads() -> None:
threads = []
# Create ten thread objects, each thread will one I/O-bound tasks
for _ in range(10):
t = Thread(target=thread_io_bound_operations, args=(1, 1))
t.start()
threads.append(t)
# Block the calling thread -> Avoids continuing to run without threads being finished
[thread.join() for thread in threads]
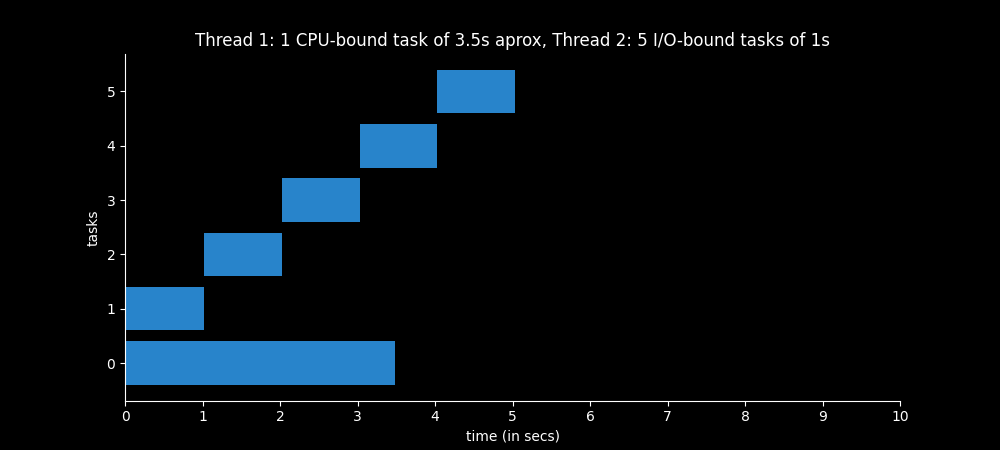
Example 7 - 2 threads
Thread 1 - 1 CPU-bound task of 3.5s approx
Thread 2 - 5 I/O-bound tasks of 1s each
Now we have two threads. The thread 1 executes one CPU-bound operation of 3.5 seconds approximately, and the thread 2 executes five I/O-bound tasks of 1 second.
While the I/O tasks are waiting the CPU intensive task is executing, as every time an I/O task begins, the OS switches from one thread to the other very quickly.
def thread_io_bound_operations(n: int, secs: float | int) -> None:
"""Run n I/O-bound tasks of secs seconds and append the results to shared_list."""
shared_list.append([io_bound_operation(secs) for _ in range(n)])
def thread_cpu_bound_operations(counts: int) -> None:
"""Run a CPU-bound task and append the results to shared_list."""
shared_list.append([cpu_bound_operation(counts)])
def threading_two_threads() -> None:
# Create two thread objects, each thread will perform five I/O-bound tasks
t1 = Thread(target=thread_cpu_bound_operations, args=(100000000,))
t2 = Thread(target=thread_io_bound_operations, args=(5, 1))
# Start activity -> invokes run() method
t1.start()
t2.start()
# Block the calling thread -> Avoids continuing to run without threads being finished
t1.join()
t2.join()
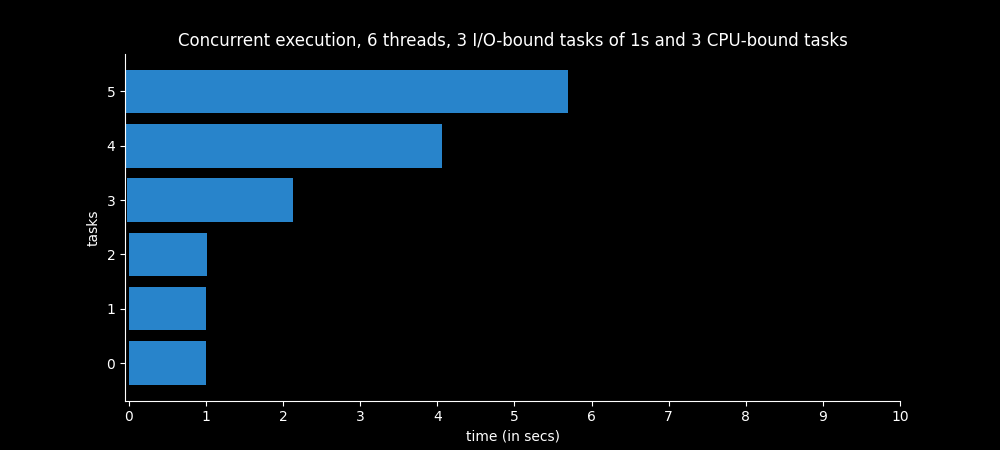
Example 8 - 6 threads
Thread 1 - 1 CPU-bound task of 3.5s approx (bar 5)
Thread 2 - 1 CPU-bound task (bar 4)
Thread 3 - 1 CPU-bound task (bar 3)
Thread 4 - 1 I/O-bound task of 1s
Thread 5 - 1 I/O-bound task of 1s
Thread 6 - 1 I/O-bound task of 1s
Here, we have three threads in charge of executing one I/O task each, and three threads in charge of executing one CPU intensive task each. The three CPU intensive tasks take different amounts of time to complete.
The longest task, which last 3.5 seconds, is the first to begin (5). It takes almost 6 seconds to complete due to the other two CPU intensive tasks.
def thread_io_bound_operations(n: int, secs: float | int) -> None:
"""Run n I/O-bound tasks of secs seconds and append the results to shared_list."""
shared_list.append([io_bound_operation(secs) for _ in range(n)])
def thread_cpu_bound_operations(counts: int) -> None:
"""Run a CPU-bound task and append the results to shared_list."""
shared_list.append([cpu_bound_operation(counts)])
def threading_six_threads() -> None:
# Create two thread objects, each thread will perform five I/O-bound tasks
t1 = Thread(target=thread_cpu_bound_operations, args=(100000000,))
t2 = Thread(target=thread_cpu_bound_operations, args=(50000000,))
t3 = Thread(target=thread_cpu_bound_operations, args=(20000000,))
t4 = Thread(target=thread_io_bound_operations, args=(1, 1))
t5 = Thread(target=thread_io_bound_operations, args=(1, 1))
t6 = Thread(target=thread_io_bound_operations, args=(1, 1))
# Start activity -> invokes run() method
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
# Block the calling thread -> Avoids continuing to run without threads being finished
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()
t6.join()
Example 9 - 4 threads
The thread 1 executes two CPU-bound operations of 3.5 seconds each sequentially (bars 6 and 7). The thread 2 executes two CPU-bound operations of almost 1 second each sequentially (bars 4 and 5).
The other bars represent the I/O-bound tasks, two of 1s for each thread.
def thread_io_bound_operations(n: int, secs: float | int) -> None:
"""Run n I/O-bound tasks of secs seconds and append the results to shared_list."""
shared_list.append([io_bound_operation(secs) for _ in range(n)])
def thread_cpu_bound_operations(counts: int, n: int) -> None:
"""Run a CPU-bound task and append the results to shared_list."""
shared_list.append([cpu_bound_operation(counts) for _ in range(n)])
def threading_four_threads() -> None:
# Create two thread objects, each thread will perform five I/O-bound tasks
t1 = Thread(target=thread_cpu_bound_operations, args=(100000000, 2))
t2 = Thread(target=thread_cpu_bound_operations, args=(20000000, 2))
t3 = Thread(target=thread_io_bound_operations, args=(2, 1))
t4 = Thread(target=thread_io_bound_operations, args=(2, 1))
# Start activity -> invokes run() method
t1.start()
t2.start()
t3.start()
t4.start()
# Block the calling thread -> Avoids continuing to run without threads being finished
t1.join()
t2.join()
t3.join()
t4.join()
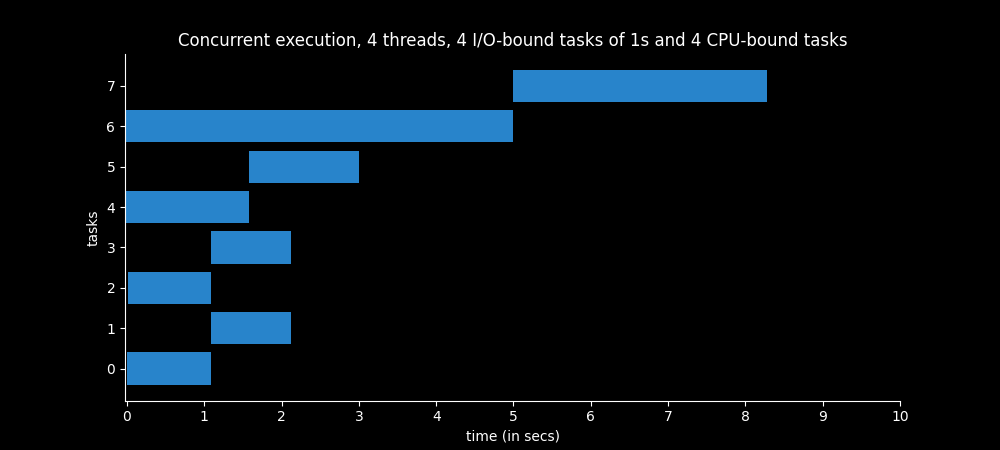
When Thread 1 (bars 6 and 7) is executing its first 3.5s CPU-bound task (bar 6), it is alternated with the other threads, so it finally takes 5s to finish execution. All the I/O-bound operations take 1s approx to finish, but while they are waiting the CPU intensive tasks can be executing. So the Thread 1 takes 5s for its first operation mainly due to the two CPU-bound operations from the Thread 2 (bars 4 and 5).
When Thread 1 (bars 6 and 7) is executing its second 3.5s CPU-bound task (bar 7), it has all the power of the processor to itself. That’s because it takes only 3.5s approx to finish.
These were some examples to clarify the concept, now let’s look at other more convenient ways to do this!
ThreadPoolExecutor
The concurrent.futures module provides a ThreadPoolExecutor object that we can use to create threads and a ProcessPoolExecutor object for multiprocessing.
As we focus on threads in this article, we will only work with ThreadPoolExecutor.
Why we need it
The ThreadPoolExecutor class is an Executor subclass that uses a pool of threads to execute calls asynchronously.
A thread pool is a software design pattern for achieving concurrency of execution in a computer program. It maintains multiple threads waiting for tasks to be allocated for concurrent execution by the supervising program.
So the ThreadPoolExecutor creates and manages a collection of threads or worker threads which can be reused, avoidind the creation and destruction of threads every time we want execute a task concurrently, as we did above. This will improve performance as these operations are time consuming.
How it works
The Executor class
As well as the ProcessPoolExecutor class, the ThreadPoolExecutor also extends the Executor class, which is an abstract base class that defines only five methods:
submit()map()shutdown()
Executorsource code Python 3.13
The other two methods are actually the __enter__() and __exit__() Python’s magic methods to implement the context management protocol. Thanks to them we can use the ThreadPoolExecutor in a with statement (recommended). The with statement will call the __enter__() method, and __exit__() will be called when the execution leaves the with code block.
class Executor(object):
"""This is an abstract base class for concrete asynchronous executors."""
...
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.shutdown(wait=True)
return False
Executor is only an abstract class and most of the logic is implemented in the ThreadPoolExecutor methods. The submit() and shutdown() methods are implemented in the ThreadPoolExecutor class while the logic for the map() method is implemented in the Executor class, since it uses submit() internally.
The ThreadPoolExecutor class
ThreadPoolExecutor in Python’s concurrent.futures module uses a queue internally to manage tasks. The queue is created in the ThreadPoolExecutor’s constructor.
ThreadPoolExecutorsource code. Python 3.13
__init__() method
The __init__() method initializes a new ThreadPoolExecutor instance and creates the queue and a few more objects.
The SimpleQueue class below is a simple, unbounded FIFO queue. If follows the First-In-First-Out principle, which specifies that an item will be processed or removed from a queue in the order in which it enters.
We can set the maximun number of threads that can be used by passing it as an argument to the max_workers parameter. If we don’t do it, it will be the number of processors in the machine plus 4, limited to 32:
class ThreadPoolExecutor(_base.Executor):
...
def __init__(self, max_workers=None, thread_name_prefix='',
initializer=None, initargs=()):
...
if max_workers is None:
# We use process_cpu_count + 4 for both types of tasks.
# But we limit it to 32 to avoid consuming surprisingly large resource
# on many core machine.
max_workers = min(32, (os.process_cpu_count() or 1) + 4)
...
self._max_workers = max_workers
self._work_queue = queue.SimpleQueue()
...
We can also pass an optional name prefix to give our threads, a callable used to initialize worker threads, and a tuple with its arguments.
submit() method
The submit() method schedules the callable to be executed. It is submitted to the thread pool. The callable is the function whose name we pass as an argument along with its arguments.
with ThreadPoolExecutor(max_workers=1) as executor:
future = executor.submit(pow, 323, 1235)
print(future.result()) # blocks
The task is wrapped in a Future object which represents the asynchronous execution of the callable, and it is returned immediately by the submit() method.
A Future is just an abstraction that represents an eventual result of an asynchronous operation, it’s an object that acts as a placeholder for a result that is initially unknown, typically because the computation of the result is yet to be completed.
concurrent.futures.Futuredocumentation.You can find the source code for the
Futureclass just above the code for theExecutorclass in the _base module for Python 3.13.
future.result() returns the value returned by the call (the pow function). If the call hasn’t yet completed then this method will wait up to timeout seconds (timeout is the only parameter of result(timeout=None)). If the call hasn’t completed in timeout seconds, then a TimeoutError will be raised. timeout can be an int or float. If timeout is not specified or None, there is no limit to the wait time.
Below we can see some of the source code for the ThreadPoolExecutor class. When the submit() method is called a Future and a _WorkItem objects are created. Then the _WorkItem is put in the _work_queue.
class ThreadPoolExecutor(_base.Executor):
...
def submit(self, fn, /, *args, **kwargs):
with self._shutdown_lock, _global_shutdown_lock:
...
f = _base.Future()
w = _WorkItem(f, fn, args, kwargs)
self._work_queue.put(w)
self._adjust_thread_count()
return f
...
The _WorkItem is an object used to wrap the task (fn), its arguments (args and kwargs) and the future object (_base.Future()) together. It implements a run() method where the task is executed and the result is set in the Future object.
class _WorkItem:
def __init__(self, future, fn, args, kwargs):
self.future = future
self.fn = fn
self.args = args
self.kwargs = kwargs
def run(self):
if not self.future.set_running_or_notify_cancel():
return
try:
result = self.fn(*self.args, **self.kwargs)
except BaseException as exc:
self.future.set_exception(exc)
# Break a reference cycle with the exception 'exc'
self = None
else:
self.future.set_result(result)
__class_getitem__ = classmethod(types.GenericAlias)
That run() method is called from the worker thread. It is implemented in the _worker module function, which is the function passed to the thread as target.
def _worker(executor_reference, work_queue, initializer, initargs):
...
if work_item is not None:
work_item.run()
# Delete references to object. See GH-60488
del work_item
continue
...
The threads are created in the _adjust_thread_count() method called in the constructor of the ThreadPoolExecutor class.
class ThreadPoolExecutor(_base.Executor):
def _adjust_thread_count(self):
...
if num_threads < self._max_workers:
thread_name = '%s_%d' % (self._thread_name_prefix or self,
num_threads)
t = threading.Thread(name=thread_name, target=_worker,
args=(weakref.ref(self, weakref_cb),
self._work_queue,
self._initializer,
self._initargs))
t.start()
self._threads.add(t)
_threads_queues[t] = self._work_queue
...
map() method
map() is directly implemented in the Executor class, and it uses the submit() method internally.
class Executor(object):
"""This is an abstract base class for concrete asynchronous executors."""
...
def map(self, fn, *iterables, timeout=None, chunksize=1):
...
fs = [self.submit(fn, *args) for args in zip(*iterables)]
...
map() is the other way we have to submit tasks to the thread pool. It is similar to the built-in map(fn, *iterables) function, but the function we pass to it as fn is executed asynchronously and several calls to fn may be made concurrently.
The built-in map() function provides lazy evaluation, meaning that values from the iterable returned by it are computed and returned only when requested.
However, when Executor.map(fn, *iterables) is called, the function gathers all the items from the provided iterables upfront. This is in contrast to a lazy evaluation approach where items are processed as they are needed (i.e., on-demand).
It returns an iterator that we can iterate over to get the values from the tasks as they are available in the same order that the iterable we provided.
If timeout is not specified or None, there is no limit to the wait time. So when we start iterating, we won’t access the second element of the iterator until the first one is available. The returned iterator raises a TimeoutError if the result isn’t available after timeout seconds when it is set to a specific int or float.
If a fn call raises an exception, then that exception will be raised when its value is retrieved from the iterator.
Let’s see an example! This example is super beatiful, I ran it about twenty times 🤭
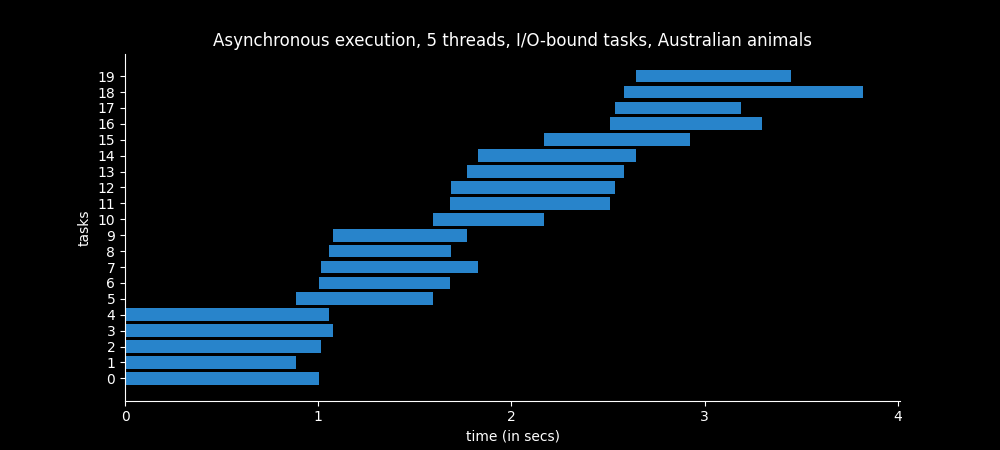
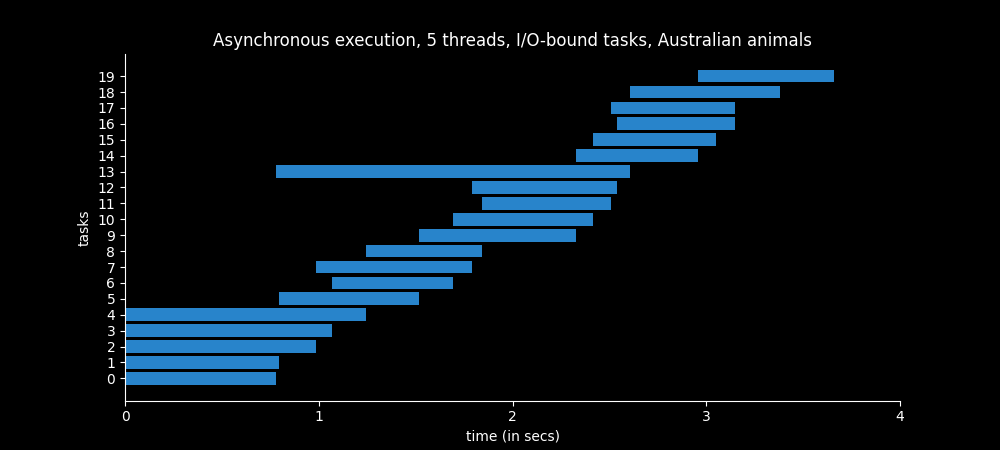
Basically we use a ThreadPoolExecutor with 5 worker threads to load 20 exotic Australian animals from Wikipedia.
Only one thread can run at a specific instant in time, but 5 threads are available. So when the first thread starts execution a context switch occur and the second thread can start, since the OS detects that it is an I/O operation and avoids wasting time resources by allocating resources to another thread.
Below we see that only 5 threads are working concurrently at any instant in time. When one thread completes the tasks, it is reused to start another task. It takes less than 4 seconds to complete.
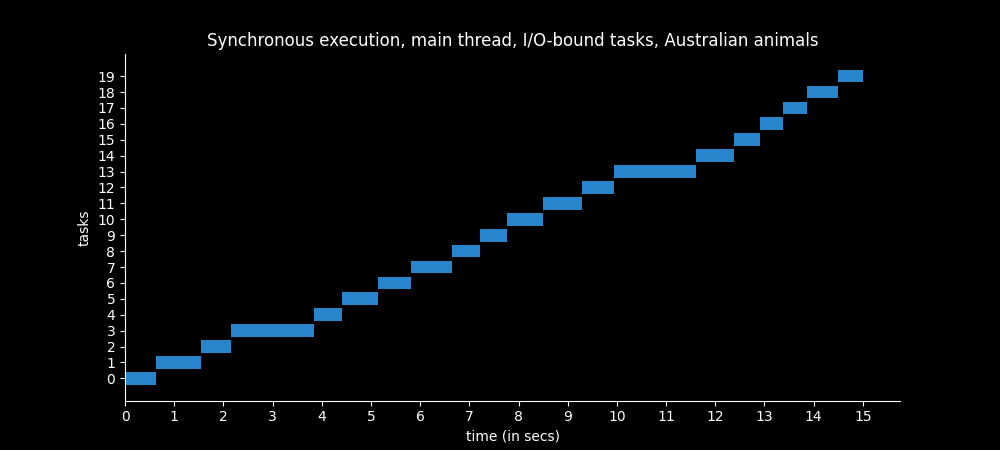
On the other hand, if we load the twenty Australian animals synchronously it takes almost fifteen seconds! 😱
You can see which are the twenty exotic Australian animals in the code.
import concurrent.futures
from time import perf_counter, time
import urllib.request
import logging
from concurrency.utils import get_saving_path, postprocess_times
from concurrency.visualize import barh
format = "%(asctime)s: %(message)s"
logging.basicConfig(format=format, level=logging.INFO, datefmt="%H:%M:%S")
URLS = [
"https://en.wikipedia.org/wiki/Emu",
"https://en.wikipedia.org/wiki/Wombat",
"https://en.wikipedia.org/wiki/Kangaroo",
"https://en.wikipedia.org/wiki/Platypus",
"https://en.wikipedia.org/wiki/Koala",
"https://en.wikipedia.org/wiki/Tasmanian_devil",
"https://en.wikipedia.org/wiki/Echidna",
"https://en.wikipedia.org/wiki/Dingo",
"https://en.wikipedia.org/wiki/Kookaburra",
"https://en.wikipedia.org/wiki/Wallaby",
"https://en.wikipedia.org/wiki/Macrotis",
"https://en.wikipedia.org/wiki/Quokka",
"https://en.wikipedia.org/wiki/Cassowary",
"https://en.wikipedia.org/wiki/Sugar_glider",
"https://en.wikipedia.org/wiki/Laughing_kookaburra",
"https://en.wikipedia.org/wiki/Rainbow_lorikeet",
"https://en.wikipedia.org/wiki/Coastal_taipan",
"https://en.wikipedia.org/wiki/Mistletoebird",
"https://en.wikipedia.org/wiki/Thylacine",
"https://en.wikipedia.org/wiki/Quoll",
]
animals = {}
# I/O-bound operation
def load_url(url: str) -> tuple[float]:
"""Retrieve a single page and return start and finish times."""
start = perf_counter()
with urllib.request.urlopen(url) as conn:
animals[url] = conn.read()
finish = perf_counter()
return start, finish
def asynchronous_load_australian_animals() -> None:
start = time()
# Use ThreadPoolExecutor to manage concurrency
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Use the map method to apply load_url to each URL
results = executor.map(load_url, URLS)
# Process the results and times
times = [time for time in results]
start_points, end_points = postprocess_times(times)
end = time()
total_time = round(end - start) + 1
barh(
title="Asynchronous execution, 5 threads, I/O-bound tasks, Australian animals",
start_points=start_points,
end_points=end_points,
path=get_saving_path("thread-pool-executor/images/ThreadPoolExecutor_ex1.png"),
n=len(URLS),
secs=total_time,
)
if __name__ == "__main__":
logging.info("Init asynchronous tasks")
asynchronous_load_australian_animals()
logging.info(f"len(animals): {len(animals)}")
logging.info("Finish asynchronous tasks")
With the submit() method it would look something like this, although it varies a lot from one run to another.
We need to use the as_completed() function to iterate over the Future instances. Otherwise our postprocess_times() function will raise an exception.
as_completed() returns an iterator over the Future instances given by results that yields futures as they complete (finished or cancelled futures).
def asynchronous_load_australian_animals() -> None:
start = time()
# Use ThreadPoolExecutor to manage concurrency
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Use the submit method to apply load_url to each URL
results = [executor.submit(load_url, url) for url in URLS]
# Process the results and times
times = [result.result() for result in concurrent.futures.as_completed(results)]
start_points, end_points = postprocess_times(times)
end = time()
total_time = round(end - start) + 1
shutdown() method
If you call ThreadPoolExecutor in a with statement as a context manager, then you won’t need to call the shutdown() method since it is called inside the __exit__() magic method. Otherwise you will need to call it to signal the executor that it should free any resources that it is using when the current pending futures have finished executing.
class Executor(object):
"""This is an abstract base class for concrete asynchronous executors."""
...
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.shutdown(wait=True)
return False
There are lots of things you can do with these tools. A Future object has several methods that you can use to customize the behaviour of your program (e.g., cancel(), running(), done(), etc.)
There is also a wait() function provided in the concurrent.futures module that allows you to wait for them to complete. You can specify when to return via the return_when parameter.
Below I leave some resources that helped me to understand this topic better.
Feel free to contact me by any social network. Any feedback is appreciated!
Thanks for reading 🙂
Other Resources
- Introduction to Concurrency and Parallelism
- threading module docs
- threading module source code. Python 3.13
- concurrent.futures module docs
- concurrent.futures module source code
queuemodule source code- thread pool Wikipedia
map(fn, *iterables)built-in function- concurrency-python repo
- Python Threading: The Complete Guide from SuperFastPython
- ThreadPoolExecutor in Python: The Complete Guide from SuperFastPython